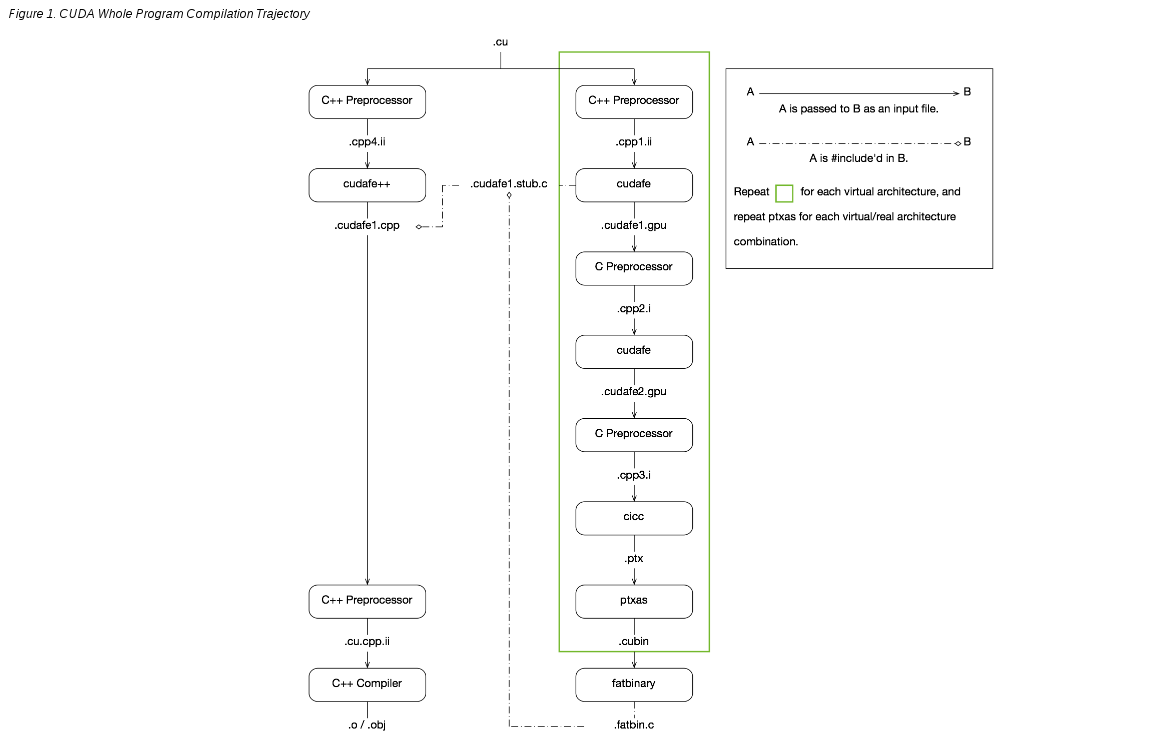
 完整的说明了如何从一个 .cu or .cpp 生成一个可执行的文件。 1.只打印,不运行
完整的说明了如何从一个 .cu or .cpp 生成一个可执行的文件。 1.只打印,不运行 nvcc -O2 -c backprop_cuda.cu -keep -arch sm_30 --dryrun 2.打印出 具体流程
1
2
1. 读取环境变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#$ _SPACE_=
#$ _CUDART_=cudart
#$ _HERE_=/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin
#$ _THERE_=/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin
#$ _TARGET_SIZE_=64
#$ TOP=/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin/..
#$ LD_LIBRARY_PATH=/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin/../lib:/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin/../extools/lib:/home/gpgpu-sim/gpgpu-sim_distribution/lib/gcc-4.6.4/cuda-4020/release:/home/gpgpu-sim/cuda/toolkit/4.2/cuda/lib64:
#$ PATH=/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin/../open64/bin:/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin/../nvvm:/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin:/home/gpgpu-sim/gpgpu-sim_distribution/bin:/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin:/home/gpgpu-sim/gcc46/:/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin:/home/gpgpu-sim/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games
#$ INCLUDES="-I/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin/../include" "-I/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin/../include/cudart"
#$ LIBRARIES= "-L/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin/../lib64" -lcudart
#$ CUDAFE_FLAGS=
#$ OPENCC_FLAGS=
#$ PTXAS_FLAGS=
以上是各种环境变量的读取,有的有,有的没有,那么从下面开始,就是上图中左侧绿框中的步骤了。
1
2
3
4
2.使用c++ 预处理器进行预处理,生成中间文件 .cpp1.ii
将一些定义好的枚举变量(例如cudaError)、struct(例如cuda的数据类型float4)、静态内联函数、extern "c++"和extern的函数、
还重新定义了std命名空间、函数模板等内容写在main函数之前。
1
2
3
4
#$ gcc -D__CUDA_ARCH__=300 -E -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -D__CUDACC__ -O2 "-I/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin/../include" "-I/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin/../include/cudart" -include "cuda_runtime.h" -m64 -o "backprop_cuda.cpp1.ii" "backprop_cuda.cu"
1
2
3
3.调用cudafe将分别执行在 host 和 device 上code 分离,生成.cudafe1.gpu
1
2
3
#$ cudafe --m64 --gnu_version=40604 -tused --no_remove_unneeded_entities --gen_c_file_name "backprop_cuda.cudafe1.c" --stub_file_name "backprop_cuda.cudafe1.stub.c" --gen_device_file_name "backprop_cuda.cudafe1.gpu" --include_file_name "backprop_cuda.fatbin.c" "backprop_cuda.cpp1.ii"
1
2
3
4.使用c 预处理器进行预处理,生成中间文件 .cpp2.i
1
2
3
#$ gcc -D__CUDA_ARCH__=300 -E -x c -DCUDA_DOUBLE_MATH_FUNCTIONS -D__CUDACC__ -O2 -D__CUDA_PREC_DIV -D__CUDA_PREC_SQRT "-I/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin/../include" "-I/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin/../include/cudart" -m64 -o "backprop_cuda.cpp2.i" "backprop_cuda.cudafe1.gpu"
1
2
3
5.继续使用cudafe进行分离?
1
2
3
4
#$ cudafe -w --m64 --gnu_version=40604 --c --gen_c_file_name "backprop_cuda.cudafe2.c" --stub_file_name "backprop_cuda.cudafe2.stub.c" --gen_device_file_name "backprop_cuda.cudafe2.gpu" --include_file_name "backprop_cuda.fatbin.c" "backprop_cuda.cpp2.i"
1
2
3
6.预处理,因为不同架构gpu的计算能力不同,那么需要进行相应的处理
1
2
3
4
#$ gcc -D__CUDA_ARCH__=300 -E -x c -DCUDA_DOUBLE_MATH_FUNCTIONS -D__CUDABE__ -D__CUDANVVM__ -O2 -D__CUDA_PREC_DIV -D__CUDA_PREC_SQRT "-I/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin/../include" "-I/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin/../include/cudart" -m64 -o "backprop_cuda.cpp3.i" "backprop_cuda.cudafe2.gpu"
1
2
3
7.filehash?
1
2
3
4
#$ filehash -s " " "backprop_cuda.cpp3.i" > "backprop_cuda.hash"
1
2
3
8.c++预处理?
1
2
3
4
#$ gcc -E -x c++ -D__CUDACC__ -O2 "-I/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin/../include" "-I/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin/../include/cudart" -include "cuda_runtime.h" -m64 -o "backprop_cuda.cpp4.ii" "backprop_cuda.cu"
1
2
3
9.将中间文件进一步分离?,生成ptx文件
1
2
3
4
#$ cudafe++ --m64 --gnu_version=40604 --parse_templates --gen_c_file_name "backprop_cuda.cudafe1.cpp" --stub_file_name "backprop_cuda.cudafe1.stub.c" "backprop_cuda.cpp4.ii"
#$ cicc -arch compute_30 -m64 -ftz=0 -prec_div=1 -prec_sqrt=1 -fmad=1 "backprop_cuda" "backprop_cuda.cpp3.i" -o "backprop_cuda.ptx"
1
2
3
4
10.将ptx,编译成.cubin
PTX离线编译,将代码编译成一个确定的计算能力和SM版本,对应的版本信息保存在cubin中。
1
2
3
#$ ptxas -arch=sm_30 -m64 "backprop_cuda.ptx" -o "backprop_cuda.sm_30.cubin"
1
2
3
4
11.将.cubin编译成 .fatbin/fatbin.c
PTX在线编译,是将cubin和ptx中的版本信息保存在fatbin中。
1
2
3
#$ fatbinary --create="backprop_cuda.fatbin" --key="xxxxxxxxxx" --ident="backprop_cuda.cu" -cuda "--image=profile=compute_30,file=backprop_cuda.ptx" "--image=profile=sm_30,file=backprop_cuda.sm_30.cubin" --embedded-fatbin="backprop_cuda.fatbin.c"
1
2
3
12.再进行预处理
1
2
3
4
#$ gcc -D__CUDA_ARCH__=300 -E -x c++ -DCUDA_DOUBLE_MATH_FUNCTIONS -O2 -D__CUDA_PREC_DIV -D__CUDA_PREC_SQRT "-I/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin/../include" "-I/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin/../include/cudart" -m64 -o "backprop_cuda.cu.cpp.ii" "backprop_cuda.cudafe1.cpp"
1
2
3
13.用c++编译器继续编译,生成.o
1
2
3
#$ gcc -c -x c++ -O2 "-I/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin/../include" "-I/home/gpgpu-sim/cuda/toolkit/4.2/cuda/bin/../include/cudart" -fpreprocessed -m64 -o "backprop_cuda.o" "backprop_cuda.cu.cpp.ii"
1
2
3
14.最后 用 gcc 将 所有的.o 链接,生成可执行文件
1
2
3
gcc -g -O2 backprop.o facetrain.o imagenet.o backprop_cuda.o -o backprop -L/home/gpgpu-sim/cuda/toolkit/4.2/cuda/lib64 -lcudart -lm
